


Алгоритмическая загадка молекулярной эволюции
А. Колесников
После того, как ученые научились читать генетические тексты наследственной информации, записанные в молекулах ДНК и РНК, выяснилось одно странное обстоятельство. Вопреки ожиданиям, основанным на классической дарвиновской теории эволюции, генетические тексты выглядели вовсе не случайными последовательностями "букв", а, напротив, оказалось, что в них присутствует строгая упорядоченность. К всеобщему удивлению выяснилось, что на самом низком и фундаментальном уровне организации живой материи наследственный код насыщен многочисленными повторяющимися фрагментами и палиндромами. Напомним, что палиндромом называется фраза или слово, которое одинаково читается с обеих сторон. Например, фраза "А роза упала на лапу Азора" без учета пробелов между словами будет читаться одинаково в обоих направлениях.
Упорядоченность генетических текстов трудно объяснить на основе классической дарвиновской теории эволюции. Краеугольным камнем дарвинизма является постулат о том, что естественный отбор векторизует случайную мутационную изменчивость. То есть изначальным сырьем для природной селекции выступают "опечатки", время от времени самопроизвольно появляющиеся в наследственных кодах. Но тогда и сами коды должны выглядеть именно как результат многочисленных случайных опечаток. В этом случае последовательность букв в генетических текстах должна быть сравнима с той, которую оставила бы на экране маленькая собачка, потоптавшись по клавиатуре компьютера. Но на самом деле твердо экспериментально установлено, что это не так. Следовательно, в природе действует некий иной механизм формирования и эволюционной трансформации наследственного кода. Иной, но какой же?
Сторонники теории номогенеза, разработанной академиком Л. С. Бергом в начале двадцатого века, склонны интерпретировать феномен упорядоченности генетических текстов как доказательство существования некой номогенетической закономерности, управляющей биологической эволюцией извне. Правда, природа самой этой закономерности так и остается загадкой.
Известно, что тексты наследственной информации передаются от родителей к потомкам путем копирования. Русский ученый-генетик Тимофеев-Ресовский, тот самый, о котором Даниил Гранин написал биографическую повесть "Зубр", называл этот процесс конвариантной матричной редубликацией. Может быть, разгадка как раз и кроется в механике этой конвариантной редубликации. Что если предположить, что наследственные тексты кодируют, в том числе и возможность своего собственного изменения. То есть тексты наследственной информации и являются носителями той закономерности, которая проявляется в их итоговой упорядоченности.
Для того, чтобы в общих чертах представить себе, как это может происходить, рассмотрим следующую алгоритмическую модель. В начале сгенерируем случайную последовательность какой-то произвольной длины n, состоящую из нерегулярно чередующихся четырех знаков (обозначим их - 1,2,3,4). Например, 1214434. В конце последовательности запишем ноль как признак завершения кода. Затем разместим эту последовательность на клеточном поле по следующим правилам (см. рисунок а).
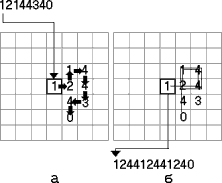
Первый символ запишем в некоторую, заранее заданную клетку. Затем, в зависимости от того, какой именно символ вписан в текущую клетку, следующий элемент последовательности будем заносить в одну из четырех ячеек, соседних с данной. Если в текущую клетку вписана единица, следующий символ разместим в правой соседней клетке; если в текущую клетку вписана двойка, следующий символ разместим в соседней верхней клетке; если в клетку вписана тройка, то следующий символ разместим в соседней левой клетке; и, наконец, если в текущую клетку вписана четверка, то следующий символ впишем в соседнюю нижнюю клетку. Точно так же поступим со следующим символом, и будем продолжать этот процесс, пока не дойдем до нуля (признака окончания последовательности) или не наткнемся на конец поля. Если в процессе записи очередная клетка окажется уже занята, то будем писать наверх, "забивая" предыдущий знак.
Информационные макромолекулы РНК и ДНК, как и любые другие полимерные молекулы, в реальных физических условиях имеют определенную пространственную форму, которая во многом определяется порядком следования мономеров в первичной информационной цепочке. Описанный выше алгоритм записи одномерной последовательности знаков на клеточное поле будем считать некой очень общей аллегорией процесса образования пространственной структуры информационной полимерной молекулы.
На следующем этапе нашей алгоритмической игры смоделируем процесс копирования исходного информационного кода. Но в качестве матрицы будем использовать не первичную линейную последовательность символов, а ее вторичную "пространственную" структуру, размещенную на клеточном поле. В природе копирование информационных биополимеров осуществляется специализированным ферментом. Особым образом организованная белковая молекула прикрепляется к молекулярным цепочкам ДНК или РНК в точке, отмеченной специальным кодом инициации, и символ за символом синтезирует ее копию. При этом если, например, на исходной матричной молекуле какой-то ее участок свернут в петлю, то существует шанс, что копирующий фермент проскочит это место или, напротив, "зациклится" и повторит его несколько раз. То есть, в принципе, вторичная пространственная структура молекул ДНК или РНК может активно влиять на содержание их дочерних копий. Так, например, "комплементарные палиндромы, способные к образованию вторичной структуры ДНК, пригодны быть горячими точками множественных и одиночных мутаций, делеций и вставок... Наиболее существенно, что комплементарные палиндромы и инвертированные повторы способны обеспечивать блочные перестройки в ходе эволюции генов"1. Иными словами, чем сложнее и причудливей будет закручена исходная молекула, тем больше вероятность различных "курьезов" в процессе ее воспроизведения. К чему все это в совокупности может привести, попытаемся разобраться, продолжив нашу алгоритмическую аллегорию.
Копирования информационной матрицы будем моделировать следующим образом. Пусть вначале, по аналогии с природным процессом репликации, воображаемый фермент или считывающая головка "садится" на помеченную ячейку клеточного поля, в которой всегда располагается первый символ. После этого в первую позицию дочерней воспроизводимой последовательности поместим символ, находящийся в этой исходной помеченной клетке. Дальнейшие правила считывания примем следующими. Головка может переместиться в одну из четырех (левую, верхнюю, правую, нижнюю), соседних с данной, но не пустых ячеек. Выбор одного из возможных вариантов будем считать равновероятным. Для усиления сходства с реальной матричной редубликацией можно запретить воображаемой считывающей головке сразу возвращаться в предыдущую позицию. Это как бы придаст процессу считывания определенную однонаправленность, но смысл результатов от этого меняется незначительно. При описанных правилах поведения считывающей головки строго упорядоченные последовательности будут копироваться однозначно, а хаотичные, сложно скрученные, напротив, будут допускать поливариантное или конвариантное воспроизведение. На рисунке б представлен один из возможных путей прочтения последовательности, изображенной на рисунке а. На примере видно, что дочерняя копия уже более упорядочена, по сравнению с исходной, так как содержит повтор.
Компьютерное моделирование описанной алгоритмической игры убеждает в том, что в подавляющем большинстве (за исключением вырожденных случаев) исходные случайные последовательности символов после нескольких циклов конвариантного воспроизведения превращаются из хаотичных в строго упорядоченные. На врезке приведено три примера компьютерного "прогона" модели.
3442144441422141312314141
344441214114141
3444412141214121412114141
34444121214121414121412121412141214114141
3444412144443
344441244124443
344441444144443
344441444144443
344441444144443
111432121324213142331414442
11121434141
111414341434141
11141434341
11141434143414111
1114143414341434111
111414341434311
111414341411
1114143414143414111
111414341434143414111
11141434143414111
1114143414143414111
111414341434143414111
1114143434341434111
1114143434143434343414343414343434143414111
1114143414111
111414341434143414111
1114143414111
11141414111
11141414111
11141414111
1213424223224133414443333333344441143112343321433
4224433333333444413334433234433144334432333144443
433333333444433
433333333444433
433333333444433
По ним можно судить о том, как из абсолютно случайных наборов символов постепенно сами собой возникают полностью симметричные палиндромы или строго периодические последовательности, очень напоминающие те, которые встречаются в реальных генетических текстах. Таким образом, если предположить, что основная причина мутационной изменчивости на молекулярном уровне организации жизни находится не вне, а внутри самих генов, то загадка молекулярной эволюции представляется логически разрешимой. Разумеется, речь идет лишь о весьма отдаленной алгоритмической аналогии, поэтому я не буду настаивать на том, что открыл механизм возникновения упорядоченности на молекулярно-генетическом уровне организации живой материи (впрочем, и сильно протестовать тоже не буду :).
1. Проблемы теории молекулярной эволюции/ Ратнер В.А., Жарких А.А., Колчанов Н.А. и др. - Новосибирск: Наука, 1985. С 196